DocuContext Demo
Experience the power of DocuContext’s groundbreaking technology as it revolutionizes document analysis and comprehension, unlocking new possibilities for efficient data extraction and understanding.
Try the co pilot feature of DocuContext now.
Please contact us for full version..
How do we do it?
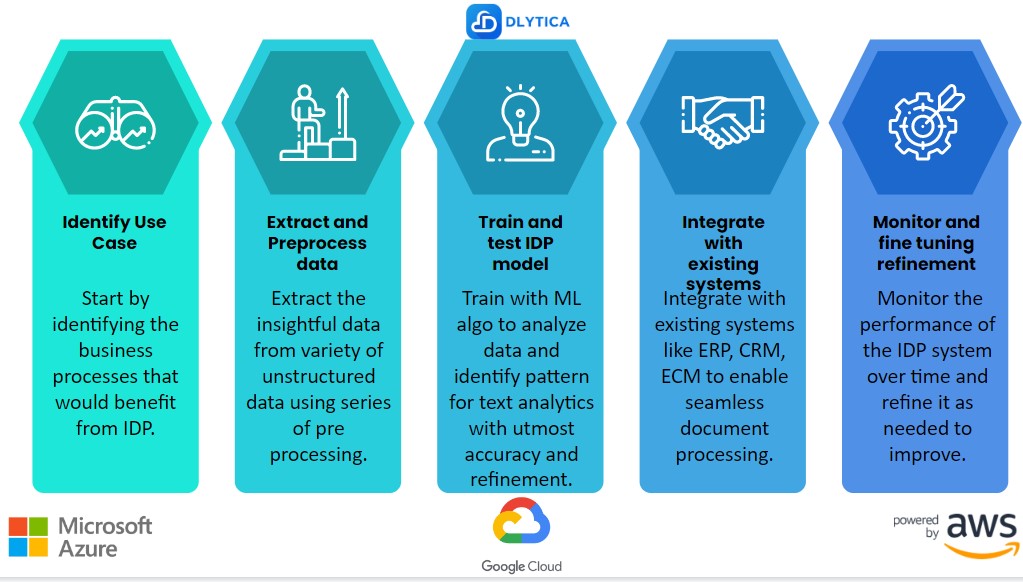
Here are the steps to implement DocuContext as intelligent document processing (IDP):
- Identify use cases: Start by identifying the business processes that would benefit from DocuContext as IDP. For instance, in the insurance industry, claims processing, policy underwriting, and customer service are some of the areas that can benefit from DocuContext powered by Generative AI like ChatGPT.
- Extract and Preprocess data: Collect a large volume of relevant data that the DocuContext system will use to train its models. The data should be in the form of the documents that will be processed, such as insurance policies, claim forms, and invoices. Before feeding the data into the IDP system, it must be preprocessed to clean it up and prepare it for machine learning. This involves tasks such as data extraction, data normalization, and data validation.
- Train and test the DocuContext IDP model: Train the DocuContext model using the preprocessed data. This involves using machine learning algorithms to analyze the data and identify patterns, which the model will use to recognize and extract information from new documents. Then, test the DocuContext model using a set of test documents to evaluate its accuracy and performance. The testing phase helps to refine the model and make it more accurate.
- Integrate with existing systems: Integrate the DocuContext system with existing software systems, such as enterprise content management (ECM) systems, to enable seamless document processing.
- Monitor and refine: Monitor the performance of the DocuContext system over time and refine it as needed to improve accuracy and performance. This involves regularly reviewing the system’s output and identifying and addressing any errors or inaccuracies.
DocuContext Claim Processing Pipeline
Data Extraction Sample
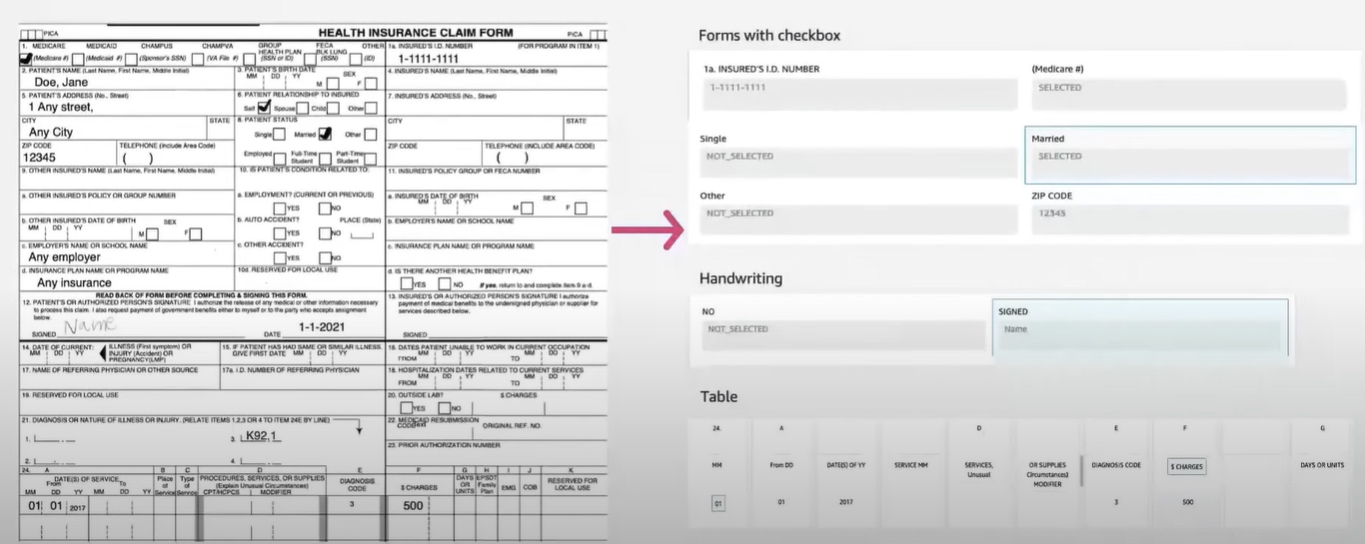
Data extraction is a critical process in DocuContext AI powered Intelligent Document Processing (IDP) that involves identifying and capturing important information from various types of documents such as invoices, receipts, forms, and contracts. The goal of data extraction is to accurately and efficiently extract the relevant information from documents and convert it into structured data that can be used for further processing or analysis.
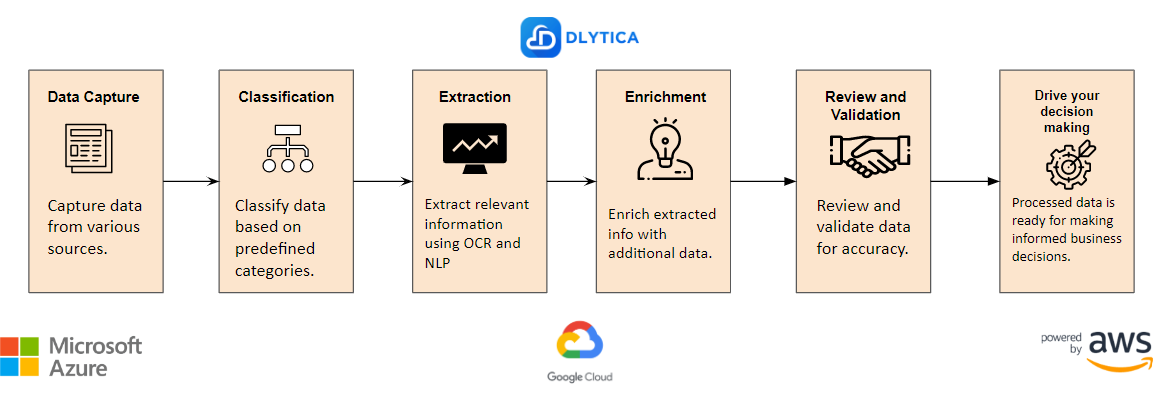
The data extraction process typically involves the following steps:
- Document Acquisition: The first step in the data extraction process is to acquire the documents that need to be processed. This can be done through scanning, uploading, or email integration.
- Preprocessing: Once the documents are acquired, they need to be preprocessed to prepare them for extraction. This can involve tasks such as converting the document to a machine-readable format, removing noise, and applying Optical Character Recognition (OCR) to recognize the text on the page.
- Document Classification: In this step, the system categorizes the document type based on predefined rules or machine learning models. This helps the system to determine which data extraction rules to apply.
- Data Extraction: This step involves extracting the relevant data from the document using predefined rules or machine learning models. The system can use techniques such as keyword spotting, regular expression matching, and Named Entity Recognition (NER) to identify and extract the data.
- Data Validation: In this step, the extracted data is validated to ensure that it is accurate and complete. This can involve comparing the extracted data to a database of known values or performing data validation checks based on business rules.
- Data Integration: The final step is to integrate the extracted data into other systems or processes. This can involve exporting the data to a database, feeding it into a workflow system, or sending it to another application for further processing.
Overall, the data extraction process in IDP is a complex task that requires a combination of techniques, including machine learning, OCR, and data validation, to accurately and efficiently extract data from various types of documents.
Pricing
Here are some of the factors to consider before we look at pricing model:
- Complexity of the project
The complexity of the project can significantly affect pricing. More complex projects may require more time and resources and, therefore, command a higher price. - Volume of documents
The number of documents to be processed will also affect pricing. The more documents that need to be processed, the higher the price. - Turnaround time
If you require a faster turnaround time, this may require additional resources and increase the pricing. - Customization
If you require customization or special features, this may require additional time and resources and increase the price. - Technology requirements and integration required
The technology requirements for the project can also affect pricing. If the project requires specialized software or hardware, this can add to the cost. - Support and maintenance
After the project are completed, you may require ongoing support and maintenance.
Boosting Efficiency
Improved Efficiency by reducing document processing times by up to 70%.
Enhancing Data Quality
63% Enhanced Data Quality improvement in data accuracy.
Revolutionizing Productivity
Increased Productivity by processing 500,000 documents per month with just six employees, compared to the 50 employees that would have been required without IDP.
Boosting Regulatory Compliance
Improved Compliance achieve up to 70% compliance with regulatory requirements.
Cutting Manual Processing Costs
Cost Savings by reducing manual document processing costs by up to 60%.
Transform Your Business Today
